This article is a summary of the past three articles (A, B, C) and a translation of an article in Japanese.
Abstract
Brain-inspired cognitive architecture is one of the options for the realization of AGI. While backpropagation has been widely used in artificial neural networks, it is not considered to be used in the brain, especially across brain regions. This paper reports the implementation of the following cognitive architectures consisting of multiple learners without backpropagation between modules:
A minimal architecture consisting of multiple learners without inter-module backpropagation
A model of cortical, basal ganglia, and thalamic loops
A model of a working memory with an attention mechanism.
Introduction
In recent years, progress has been made in the field of machine learning using artificial neural networks (ANNs). In agent learning with ANNs, end-to-end deep reinforcement learning with backpropagation is the mainstream. Meanwhile, it is hoped that cognitive architectures inspired by animal brains will serve as an approach to AGI. Since backpropagation may not occur in the animal brain (at least not across brain regions), I have attempted to implement three cognitive architectures consisting of learners without inter-module backpropagation.
In the implementations, modules modeled after the cerebral cortex and basal ganglia were incorporated. The cortex is thought to process input into forms useful for making survival decisions and making predictions and control outputs. The basal ganglia are thought to control the timing of the cortex's external outputs with reinforcement learning.
The cortex is composed of multiple regions, and there is a hierarchy among the regions, especially in sensory areas. In "deep learning," learning is performed in a hierarchical manner that mimics the hierarchy, based on the assumption that errors are propagated backward across regions. However, in the animal brain, there is no way for errors to propagate across regions. A more biologically plausible hypothesis is that each region learns to minimize prediction errors (predictive coding).
Regular (deep) reinforcement learning assumes that a single learner controls task-specific outputs. In the brain, multiple cortical areas with their corresponding basal ganglia are in charge of controlling motions and brain areas. Thus, brain-inspired cognitive architectures would have to incorporate multiple reinforcement learners.
With the consideration above, this article reports the three implementations:
a minimal architecture incorporating multiple learners
the cortio-BG-thalamic loop
working memory with attention mechanism
Implementation frameworks
The following frameworks were used.
Environment framework
Open AI Gym, a widely used environment framework, was used.
Cognitive Architecture Description Framework
BriCA (Brain-inspired Computing Architecture), a computing platform for developing brain-inspired software, was used to describe the cognitive architecture (agent definition) [1]. BriCA has a mechanism for modules to exchange numerical vector signals in a token passing manner. Modules can also be nested.
Machine learning framework
PyTorch was used as the ANN implementation framework, and TensorForce was used as the reinforcement learning framework. With TensorForce, internal environments are easily set up.
Implementation attempt
Verifying the working of a minimal architecture with multiple learners
An architecture with BriCA was implemented consisting of two modules: a module containing a simple autoencoder (with PyTorch) as the cortical part, and a module containing a reinforcement learner (with TensorForce) with an internal environment set up as the basal ganglia part. The Cart-Pole task of the Gym (input is a 4-dimensional numerical vector) was used for testing. The autoencoder was pre-trained with environment input obtained from random output.
Since the token-passing cycle of BriCA is not the same as that of the external environment, tokens corresponding to the cycles of the external environment were set in the internal implementation so that the internal processing proceeds according to the cycles of the external environment. Specifically, the internal processing is performed as the value of the token increases by one.
See the GitHub page for the code and results.
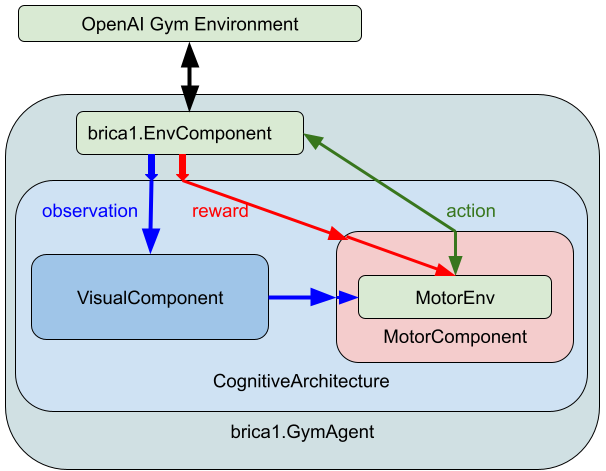
Fig. 1
Implementation of the cortico-BG-thalamic loop
The implementation is an attempt to realize the action selection and execution thought to be realized by the cortico-BG-thalamic circuit with minimal mechanisms. The mechanisms to be implemented are based on the following hypotheses.
Hypotheses
The cortex selects (predicts) actions. The basal ganglia make judgments about whether the cortex's choices are suitable for execution (and disinhibit the thalamus). The basal ganglia, as a reinforcement learner, receives information on the input to the cortex (State) and the choice being made (Action), selects Go/NoGo, and then receives a reward to learn the policy of State+Action ⇒ Go/NoGo. Meanwhile, the cortex learns from the executed State-Action pairs and predicts (selects) the appropriate State ⇒ Action.
The following provide background that corroborates the hypotheses.
On the fact that the basal ganglia do not make action choices:
The thalamic matrix subject to basal ganglia inhibition may not be "fine grained" enough to accommodate choices (e.g., mini-columns).
The number of GPi cells in the basal ganglia that inhibit (deinhibit) the thalamus may be fewer than the number of minicolumns in the cortex (whether the minicolumns are coding choices is arguable).
The basal ganglia are said to control the timing of action initiation.
Reinforcement learning in the basal ganglia is necessary to cope with delayed reward.
The hypotheses reconcile the role of reinforcement learning in the basal ganglia with prediction in the cortex.
Implementation
The outline of the implementation is described below.
See the GitHub page for the code and results.
Cerebral cortex part
Receives observation input and outputs action selection (prediction).
Output prediction layer: learns to predict an action from "observed input" using the action selected in the basal ganglia as the teacher signal. A three-layer perceptron was used for implementation.
Output adjustment layer: calculates outputs using the outputs from the output prediction layer and noise as inputs. The noise creates random output. The contribution of noise decreases as the output prediction layer learns to make correct predictions (the task correctness rate was used as the probability of using output prediction).
Output gating layer: The largest of the output adjustment layer outputs was selected (winner-take-all) and gated with a Go/NoGo signal from the basal ganglia.
Thalamus part
In this implementation, the Go/NoGo from the basal ganglia was directly transmitted to the output gate layer in the cortex, and the implementation was omitted.
Basal ganglia part
Reinforcement learning of the Go/NoGo decision was performed using the observed input + output layer output (binarized by threshold) as states.
Overall Architecture
Figure 2 shows the implementation outline and the connections between parts.

Figure 2
Test task
A minimal delayed reward task was set up in which the reward was given a few steps after the cue-observed action selection.
Learning in the Basal Ganglia part
Though TensorForce reinforcement learning algorithms (Vanilla Policy Gradient, Actor-Critic, and Proximal Policy Optimization) were tried, learning was not stable or did not occur. Thus, a frequency-based learning algorithm was implemented, which resulted in learning convergence after about 1,000 episodes.
Learning in the Cortex part
A three-layer perceptron was used to learn the cortical output when the basal ganglia part produced a Go with the external environmental input. The correct response rate for the task was used as the probability of using predictions as the output candidate for which the basal ganglia part makes a Go/NoGo decision (if predictions are not used, the output candidate is randomly determined). Loss values (cross-entropy) converged around 0.25 after about 1000 episodes (the reason for this would be that randomness remains in the selection of actions in the setting.)
Implementation of working memory with attention mechanism
Remembering items in a task (working memory) is necessary for cognitive tasks. Since animals (including humans) can only memorize a limited number of items at a time, it is thought that attention is used to narrow down the number of items. Here an implementation of working memory was made with a minimal form of attention mechanism using a simplified delayed match-to-sample task.
The implementation here is based on the following hypotheses about working memory.
The decision of which input the working memory should retain is an action selected by the PFC (prefrontal cortex) (action that directs attention to a specific item).
Which input the working memory should retain is selected by the PFC⇔Th loop (PFC-Th-BG loop), which is controlled by the BG as in other actions, and is then put into action.
The selection of which working memory to keep is exclusive, as in other actions, and only one is executed at a time in the dlPFC (dorso-lateral PFC).
Working memories are retained for a certain period of time by the activity of bi-stable neurons or other neurons in the PFC, and for longer retention, "reselection" by the PFC-Th-BG loop is required.
The frontal cortex uses the information retained in working memory and the sensory information to predict and execute actions to solve the task.
While PBWM [2] is known as a model of working memory, it was not adopted here as it may not be so biologically plausible:
It states that the basal ganglia gate sensory input, but it is the cortical output to the thalamic loop that is gated by the basal ganglia.
It states that working memory is retained during NoGo, which is the default state for the basal ganglia, but if that is the case, working memory retention becomes the default.
Specific mechanism
The implementation consists of three modules: an input register, a register controller, and an action determiner. The input register is the core part of working memory that does not learn. The other two modules learn.
See the GitHub page for details on the code and results.
Input register
Its input is an observation input and input holding signal (attention signal). When an input holding signal is given, the specified portion of the observation input is held for a specified period of time, and the output is whether the specified portion of new observation input matches the held content (recognition).
The implementation is simply a "register" with a comparator added. It corresponds to short-term memory in the prefrontal cortex.
Register controller
It determines the observed inputs (attributes) of the input register to be retained from the observed inputs and sends an attention signal to the corresponding input register (only once per episode).
The cortico-BG-thalamic loop implementation described in the previous section was used for learning.
Action determiner
It determines the action to be output to the external environment (only once per episode) from the reaffirmation signal.
The cortico-BG-thalamic loop implementation described in the previous section was used for learning.
Architecture

Figure 3
Learning
Learning based on rewards from the external environment took place at two locations: the action determiner and the register controller.
It was hoped that the two learnings would increase task success in a bootstrapping fashion, but since this did not work, curriculum learning was attempted. Specifically, first, one learner was replaced with a "stub" that outputs the correct solution to train the other learner. And then, the trained learner was used to train the former learner. The reward per action and the percentage of correctly set working memories barely exceeded 0.5, whether the action determiner or the register controller was used as the stub first.
The number of episodes required for learning exceeded 10,000.
Discussion
Here, attempts to implement architectures that incorporate multiple learners that learn in a non-end-to-end fashion were reported.
Three implementations of an architecture encompassing multiple learners with BriCA were examined. Currently a tool that wraps the cumbersome coding with BriCA is being prepared.
The current implementation of the hypothesis of working memory control by attention did not perform adequately. Since more complex tasks require a larger search space, it would be better to think of a way in which learning occurs over a biologically plausible range of episodes.
The search space should be reduced to improve learning efficiency. For diachronic multiple-action learning, a (biologically plausible) mechanism that memorizes a series of observations/actions that led to success and uses them as hypotheses to test similar cases should be devised.
A mechanism such as the one attempted here will be incorporated into a whole-brain architecture that follows the connections between regions of the whole brain (connectome), and the above issues must be resolved to guarantee its working.
References
[1] Koichi Takahashi, et al., (2015) A Generic Software Platform for Brain-inspired Cognitive Computing, Procedia Computer Science, Volume 71,
DOI: 10.1016/j.procs.2015.12.185
[2] O'Reilly, R., Frank, M. (2006) “Making working memory work: a computational model of learning in the prefrontal cortex and basal ganglia.” Neural Comput., DOI: 10.1162/089976606775093909
No comments:
Post a Comment